Combine transformers with imperio CombinatorTransformer


Very often we would like to combine different transformations on different columns of our feature matrix in a pipeline. That need motivated us to a special module that gives you this opportunity in imperio — CombinatorTransformer.
How CombinatorTransformer works?
CombinatorTransformer allows you to apply a specific feature transformation on a specific set of columns. Mostly it was created to apply a transformation to numerical columns and another to categorical columns as shown below:
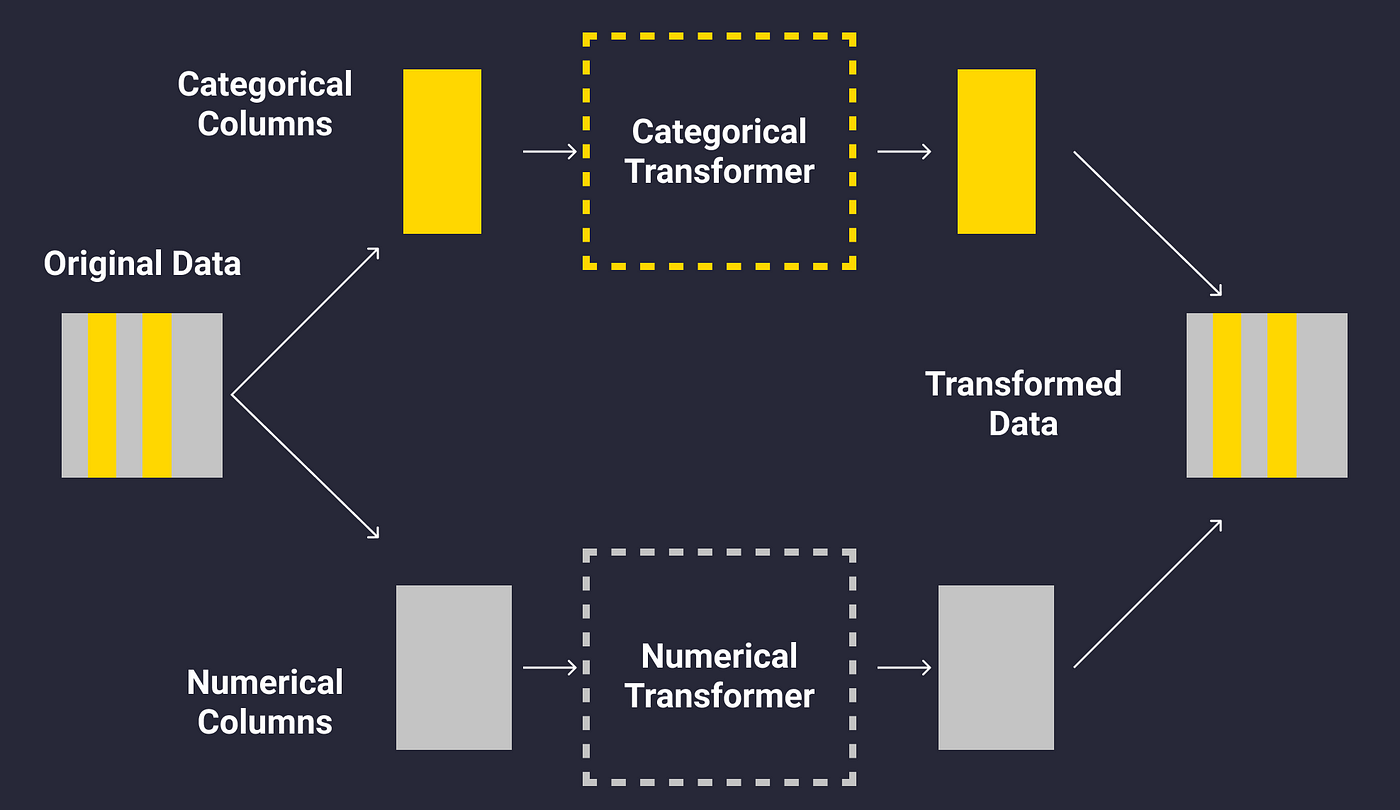
How to use CombinatorTransformer.
All transformers from imperio follow the transformers API from sci-kit-learn, which makes them fully compatible with sci-kit learn pipelines. First, if you didn’t install the library, then you can do it by typing the following command:
pip install imperio
To create a CombinatorTransformer you will need first to import some transformers. For example, I will import the FrequencyImputationTransformer for categorical columns and BoxCoxTransformer for numerical ones. Next, you must set up the CombinatorTransformer like this.
from imperio import FrequencyImputationTransformer, BoxCoxTransformer, CombinatorTransformercombinator = CombinatorTransformer(
num_index = [0, 3, 4, 7, 9],
cat_index = [1, 2, 5, 6, 8, 10, 11, 12],
num_transformer = BoxCoxTransformer(),
cat_transformer = FrequencyImputationTransformer()
)
Following the sci-kit learn API for transformers, you can fit a transformer and make some transformations:
combinator.fit(X_train, y_train)
X_transformed = combinator.transform(X_train)
Even more, you can fit and transform the data at the same time using the fit_transform function:
X_trainsformed = combinator.fit_transform(X_train, y_train)
Besides the general sci-kit learn API, you can use the apply function to apply the transformer on a pandas Data Frame:
new_df = combinator.apply(df,
target = 'target',
num_columns = ['num1', 'num2'],
cat_columns = ['cat1', 'cat2']
)
The CombinatorTransformer constructor has the following arguments:
- cat_index (list, default = None): A parameter that specifies the list of indexes of categorical columns that the categorical transformer will be applied on.
- num_index (list, default = None): A parameter that specifies the list of indexes of numerical columns that the numerical transformer will be applied on.
- cat_transformer (default = None): The sklearn or imperio transformer to apply on categorical columns.
- num_transformer (default = None): The sklearn or imperio transformer to apply on numerical columns.
The apply function has the following arguments.
- df (pd.DataFrame): The pandas DataFrame on which the transformer should be applied.
- target (str): The name of the target column.
- cat_columns (list, default = None): The list with the names of categorical columns on which the categorical transformer should be applied.
- num_columns (list, default = None): The list with the names of numerical columns on which the numerical transformer should be applied.
Below you can see an example of a Pipeline built with CombinatorTransformer and under it the comparison of confusion matrices of a simple LogisticRegression and the pipeline. These additional modules gave us 4% to the accuracy of the model on the Heart Disease UCI data set.
pipe = Pipeline(
[
('combinator', CombinatorTransformer(
num_index = [0, 3, 4, 7, 9],
cat_index = [1, 2, 5, 6, 8, 10, 11, 12],
num_transformer = BoxCoxTransformer(),
cat_transformer = FrequencyImputationTransformer()
)),
('scaler', StandardScaler()),
('model', LogisticRegression())
]
)


Made with ❤ by Sigmoid.